.){kind=link}
AMD dio a conocer información sobre la nueva arquitectura de juegos AMD RDNA, que proporciona un análisis técnico de la arquitectura subyacente que alimenta las tarjetas gráficas basadas en «Navi», incluidas las nuevas GPUs Radeon Serie RX 5700.
Introducción
El mundo de los gráficos ha evolucionado y cambiado fundamentalmente en el transcurso de las últimas tres décadas hacia una mayor capacidad de programación. Los primeros sistemas gráficos se implementaron únicamente en software y se ejecutaron en CPU, pero no podían ofrecer el rendimiento necesario para más que los efectos visuales más básicos. Las primeras arquitecturas gráficas especializadas tenían una función casi puramente fija y solo podían acelerar un rango muy limitado de cálculos 2D o 3D específicos, como la geometría o las transformaciones de iluminación. La próxima ola de arquitecturas introdujo sombreadores gráficos que les dieron a los programadores un poco de flexibilidad, pero con limitaciones estrictas. Más recientemente, los procesadores gráficos evolucionaron hacia la capacidad de programación, ofreciendo sombreadores de gráficos programables y computación de uso general.
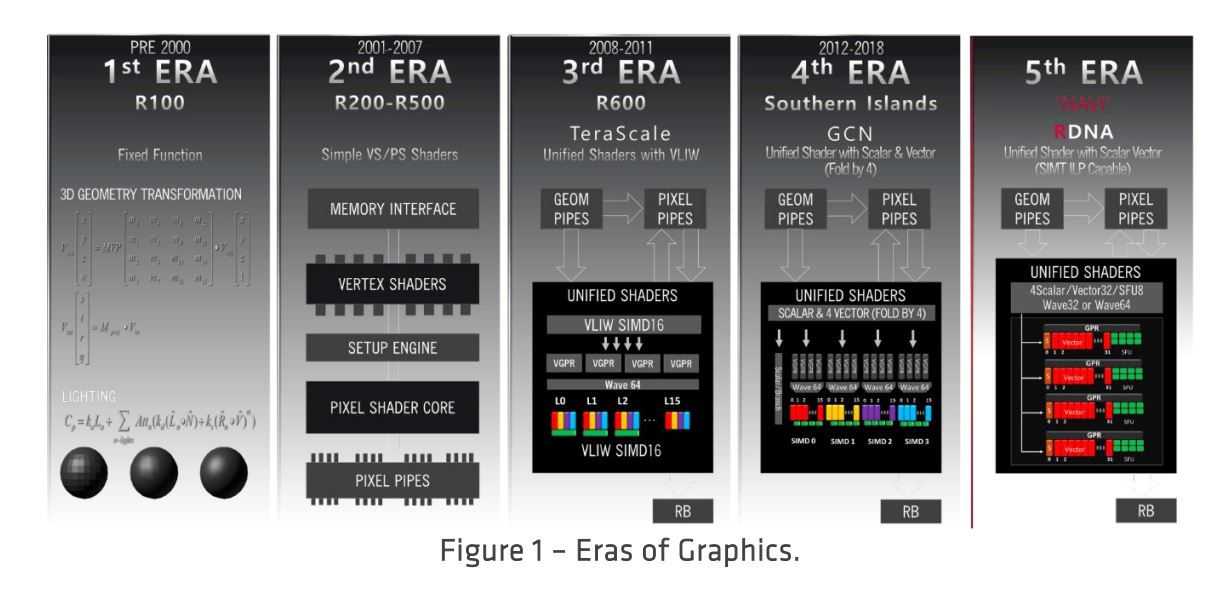
TeraScale de AMD fue diseñado para la era de los gráficos programables y marcó el comienzo del cómputo de uso general con la API DirectCompute de DirectX 11 y una arquitectura basada en VLIW. La arquitectura Graphics Core Next (GCN) se movió a un modelo de computación vectorial intercalada más programable e introdujo la computación asincrónica, permitiendo que los gráficos tradicionales y la computación general trabajen juntos de manera eficiente. La arquitectura GCN se encuentra en el corazón de más de 400 millones de sistemas, desde computadoras portátiles hasta computadoras de escritorio para juegos extremos, consolas de juegos de vanguardia y servicios de juegos en la nube que pueden llegar a cualquier consumidor en una red.
Mirando hacia el futuro, el desafío para la próxima era de los gráficos es alejarse de los gráficos pipeline convencionales y sus limitaciones a un mundo informático donde el único límite en los efectos visuales es la imaginación de los desarrolladores. Para cumplir con los desafíos de los gráficos modernos, la arquitectura RDNA de AMD es escalar, diseñada desde cero para una informática eficiente y flexible, que se puede escalar en una variedad de plataformas de juego. La familia de GPU «Navi» de 7 nm es la primera instancia de la arquitectura RDNA e incluye la serie Radeon RX 5700.
Arquitectura del sistema RDNA
Los procesadores gráficos (GPU) construidos en la arquitectura RDNA abarcarán desde computadoras portátiles y teléfonos inteligentes con bajo consumo de energía hasta algunas de las supercomputadoras más grandes del mundo. Para acomodar tantos escenarios diferentes, la arquitectura general del sistema está diseñada para una escalabilidad extrema al tiempo que aumenta el rendimiento en comparación con las generaciones anteriores. La Figura 4 a continuación ilustra el Radeon RX 5700 XT de 7 nm, que es una de las primeras encarnaciones de la arquitectura RDNA.
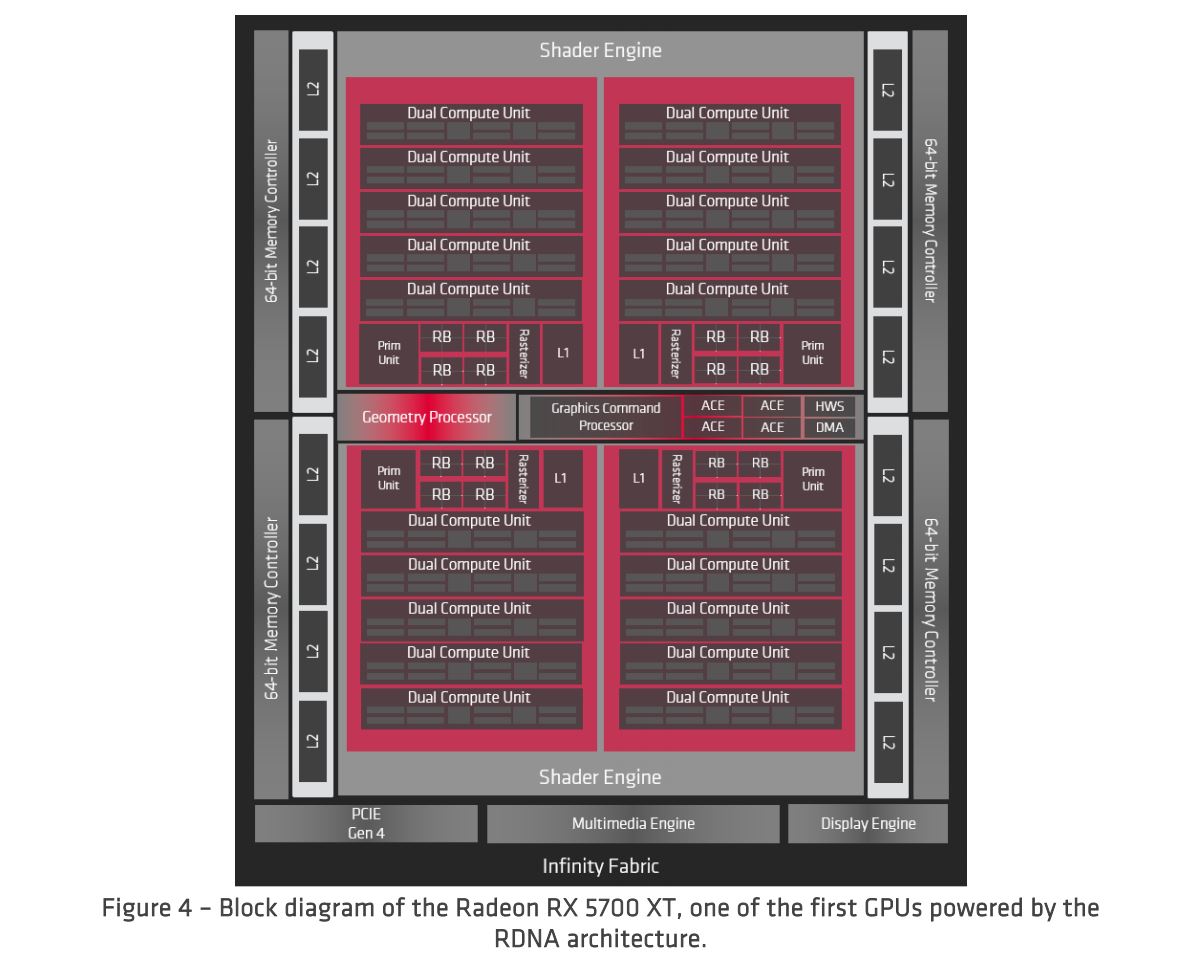
El RX 5700 XT está organizado en varios bloques principales que están unidos entre sí utilizando el Infinity Fabric de AMD. El procesador de comandos y la interfaz PCI Express conectan la GPU al mundo exterior y controlan las funciones variadas. Los dos motores de sombreado albergan todos los recursos informáticos programables y parte del hardware gráfico dedicado. Cada uno de los dos motores de sombreado incluye dos conjuntos de sombreadores, que comprenden las nuevas unidades de cómputo duales, un caché L1 de gráficos compartidos, una unidad primitiva, un rasterizador y cuatro backends de renderizado (RB). Además, la GPU incluye lógica dedicada para el procesamiento multimedia y de visualización. El acceso a la memoria se enruta a través de la caché L2 particionada y los controladores de memoria.
La arquitectura RDNA es la primera familia de GPU que utiliza PCIe 4.0 para conectarse con el procesador host. El procesador host ejecuta el controlador, que envía comandos de API y comunica datos hacia y desde la GPU. La nueva interfaz PCIe 4.0 funciona a 16 GT / s, que es el doble del rendimiento de las GPU anteriores basadas en PCI-E 3.0 de 8 GT / s. En una era de texturas inmersivas 4K u 8K, un mayor ancho de banda del enlace ahorra energía y aumenta el rendimiento.
El agente hipervisor permite que la GPU se virtualice y se comparta entre diferentes sistemas operativos. La mayoría de los servicios de juegos en la nube viven en centros de datos donde la virtualización es crucial desde el punto de vista operativo y de seguridad. Si bien las consolas modernas se centran en los juegos, muchas ofrecen un amplio conjunto de capacidades de comunicación y medios y se benefician de la virtualización del hardware para ofrecer rendimiento para todas las tareas.
El procesador de comandos recibe comandos API y, a su vez, opera diferentes canales de procesamiento en la GPU. El procesador de comandos gráficos gestiona las tareas de sombreadores de pipeline gráfica tradicional (por ejemplo, DirectX, Vulkan, OpenGL) y el hardware de función fija. Las tareas de cómputo se implementan utilizando los motores de cómputo asíncrono (ACE), que administran sombreadores de cómputo. Cada ACE mantiene una secuencia independiente de comandos y puede enviar frentes de onda de sombreado de cómputo a las unidades de cómputo. Del mismo modo, el procesador de comandos gráficos tiene una secuencia para cada tipo de sombreador (por ejemplo, vértices y píxeles). Todo el trabajo programado por el procesador de comandos se distribuye entre las unidades de función fija y la matriz de sombreadores para obtener el máximo rendimiento.
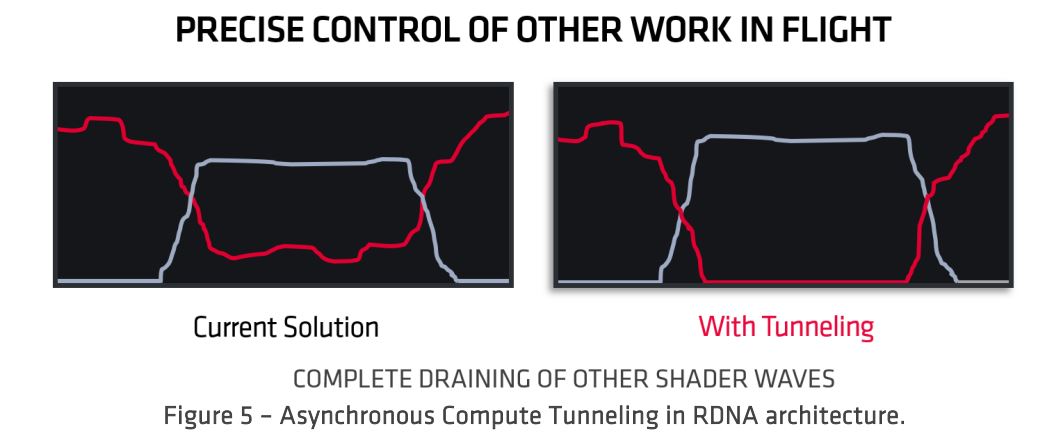
La arquitectura RDNA presenta una nueva característica de programación y calidad de servicio conocida como Asynchronous Compute Tunneling que permite que las cargas de trabajo de cómputo y gráficos coexistan armoniosamente en las GPU. En funcionamiento normal, muchos tipos diferentes de sombreadores se ejecutarán en la unidad de cómputo RDNA y avanzarán. Sin embargo, a veces una tarea puede volverse mucho más sensible a la latencia que otro trabajo. En generaciones anteriores, el procesador de comandos podría priorizar los sombreadores de cómputo y reducir los recursos disponibles para los sombreadores de gráficos. Como ilustra la Figura 5, la arquitectura RDNA puede suspender completamente la ejecución de sombreadores, liberando todas las unidades de cómputo para una tarea de alta prioridad. Esta capacidad de programación es crucial para garantizar experiencias perfectas con las aplicaciones más sensibles a la latencia, como un audio realista y la realidad virtual.
Caché de gráficos compartidos L1
Si bien pasar a una nueva tecnología de proceso como 7nm reduce el área y la potencia de los transistores, uno de los mayores desafíos es que el rendimiento y la eficiencia de los cables tienden a permanecer igual o empeorar. En consecuencia, enviar datos a largas distancias se vuelve cada vez más costoso. Para abordar este desafío, la arquitectura RDNA introduce un nuevo caché L1 de gráficos como se muestra en la Figura 11. El caché L1 de gráficos se comparte en un grupo de unidades de cómputo duales y puede satisfacer muchas solicitudes de datos, reduciendo los datos que se transmiten a través del chip, lo que aumenta el rendimiento y mejora del consumo de energía. Además, el caché L1 de gráficos intermedios mejora la escalabilidad y simplifica el diseño del caché L2.
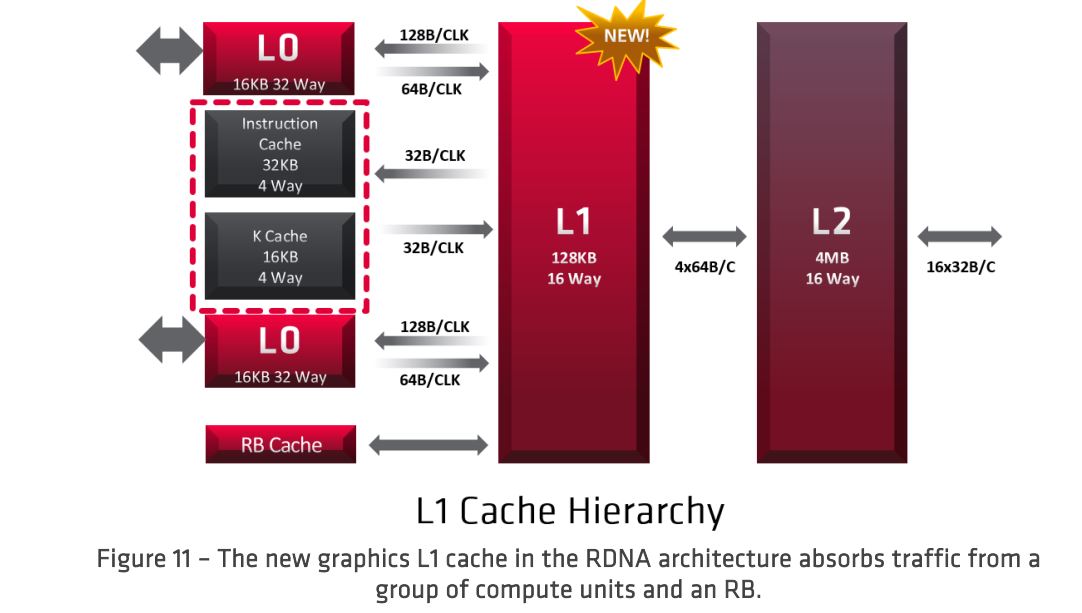
En la arquitectura GCN, la memoria caché global L2 fue responsable de atender todas las fallas de las memorias caché L1 por núcleo, las solicitudes de los motores de geometría y los back-end de píxeles, y cualquier otra solicitud de memoria. En contraste, los gráficos RDNA L1 centralizan todas las funciones de almacenamiento en caché dentro de cada matriz de sombreadores. Los accesos desde cualquiera de los cachés L0 (instrucciones, datos escalares o vectoriales) pasan a los gráficos L1. Además, los gráficos L1 también atienden solicitudes de los motores de píxeles asociados en la matriz de sombreadores.
La memoria caché L1 de gráficos es una memoria caché de solo lectura respaldada por los gráficos L2 compartidos globalmente; una escritura en cualquier línea en los gráficos L1 invalidará esa línea y golpeará en la L2 o la memoria. Hay un modo de control de derivación explícito para que los sombreadores puedan evitar poner datos en los gráficos L1.
Al igual que el caché de vector L0, cada línea tiene 128 bytes, lo que es consistente con la solicitud típica de una unidad de cálculo dual. Cada L1 es de 128 KB con cuatro bancos y es un conjunto asociativo de 16 vías. El controlador de caché L1 arbitrará entre las solicitudes de memoria entrantes y seleccionará cuatro para dar servicio a cada ciclo de reloj. Los accesos de memoria que faltan en la memoria caché L1 de gráficos se enrutan a la memoria caché L2.
2 Cache y Memoria
Una clara ventaja de la jerarquía de caché RDNA es que todas las solicitudes de memoria al caché L2 se enrutan a través de los cachés de gráficos L1. Cada conjunto de sombreadores comprende 10-20 agentes diferentes que solicitan datos, pero desde la perspectiva de la caché L2, solo los gráficos L1 solicitan datos. Al reducir el número de posibles solicitantes, los buses de datos en chip son más simples y fáciles de enrutar.
El caché L2 se comparte en todo el chip y se divide físicamente en varios segmentos. Cuatro segmentos de la caché L2 están asociados con cada controlador de memoria de 64 bits para absorber y reducir el tráfico. La memoria caché es asociativa de conjuntos de 16 vías y se ha mejorado con líneas de memoria caché de 128 bytes más grandes para que coincida con la solicitud de memoria wave32 típica. Los cortes son flexibles y se pueden configurar con 64 KB-512 KB, dependiendo del producto en particular. En el RX 5700 XT, cada segmento es de 256 KB y la capacidad total es de 4 MB.
Los controladores de memoria y las interfaces para la arquitectura RDNA están diseñados para aprovechar GDDR6, la memoria gráfica convencional más rápida. Cada controlador de memoria maneja dos DRAM GDDR6 de 32 bits con una interfaz de 16 Gbit / s, duplicando el ancho de banda disponible de la generación anterior GDDR5 dentro de aproximadamente el mismo presupuesto de energía.
Radeon Multimedia y motores de visualización
La familia de GPU «Navi» también incluye motores de procesamiento especializados extremadamente eficientes para decodificación, codificación y visualización de video.
En muchos casos, la codificación y decodificación de video se puede realizar en software en las unidades de doble computación RDNA para obtener la más alta calidad. Sin embargo, el hardware dedicado siempre producirá el mejor rendimiento y la mejor eficiencia de energía al tiempo que libera unidades de cómputo duales para otras tareas. El motor de video se ha mejorado con soporte para decodificación VP9, mientras que las generaciones anteriores dependían de implementaciones de software.
El motor de video puede decodificar transmisiones H.264 a alto rendimiento: 1080p a 600 cuadros / seg (fps) y 4K a 150 fps y puede codificar simultáneamente a aproximadamente la mitad de la velocidad: 1080p a 360 fps y 4K a 90 fps. La decodificación 8K está disponible a 24 fps para HVEC y VP9. Para una compresión más avanzada, el motor de video ofrece una decodificación de alto rendimiento para colores de 8 o 10 bits: 360 fps para una transmisión de 1080p, 90 fps para una transmisión de 4K y 24 fps para una transmisión de 8K. El codificador está diseñado para HVEC, mientras que el decodificador también puede manejar VP9.

En última instancia, los gráficos por computadora son un problema de extremo a extremo. A medida que una aplicación aprovecha las características adicionales y los nuevos efectos informáticos para crear experiencias más inmersivas, la pantalla debe mantener el ritmo y traducir las visualizaciones generadas por computadora a la realidad. El motor de pantalla RDNA fue rediseñado y optimizado principalmente para pantallas 4K y 8K y alto rango dinámico (HDR).
La salida HMDI ofrece la velocidad completa de 18 Gbps de HDMI 2.0b para permitir 4K a 60 Hz o 1080P a 240 Hz. La conexión DisplayPortTM 1.4a tiene el mismo ancho de banda sin procesar, hasta 32.4 Gbps sobre los cables existentes, pero agrega Display Stream Compression (DSC), que permite el soporte futuro de pantallas de hasta 8K HDR a 60 Hz y 4K HDR a 240 Hz.
DSC es un algoritmo de compresión estándar de la industria, de baja latencia y sin pérdidas visuales que fue desarrollado y ratificado por VESA. DSC puede comprimir video sin submuestreo de croma (4: 4: 4) a tan solo 8 bits / píxel tanto para HDR como para SDR. Esto permite operar una pantalla 4K HDR a 144 Hz y más sin sacrificar la calidad de la imagen; por ejemplo, los sistemas tradicionales sin DSC requieren submuestreo de croma (4: 2: 2 o 4: 2: 0), lo que puede introducir artefactos de color. DSC comprime las transmisiones HDR y SDR a la misma velocidad de bits, lo que permite su uso intercambiable y evita cualquier pérdida de calidad visual (por ejemplo, reducir la resolución o la frecuencia de actualización) debido a las limitaciones del cable de la pantalla.
True Audio Next
El kit de herramientas True Audio Next es un gran ejemplo de la aplicación de efectos informáticos para mejorar el realismo y crear una experiencia más inmersiva. True Audio Next puede modelar con precisión 256 canales de audio utilizando trazados de rayos físicamente precisos y efectos posicionales para simular entornos complejos.
El audio en tiempo real es aún más latente y sensible a las fluctuaciones que los gráficos, y este enfoque solo es posible debido a varias características centradas en el cómputo. Primero, la GPU puede particionar las matrices de sombreadores y reservar unidades de cómputo seleccionadas únicamente para tareas de audio, asegurando una baja latencia y una ejecución predecible. En segundo lugar, True Audio se basa en dos colas de tareas en tiempo real administradas por ACE. Una cola se usa para computar el trazado de rayos de audio usando la biblioteca de código abierto Radeon Rays, la otra se usa para calcular los efectos convolucionales para el audio posicional y la reproducción de sonido envolvente completo. El uso de dos colas separadas permite usar el rendimiento de las unidades de cómputo duales para efectos de audio deterministas y de baja latencia.
Efectos visuales avanzados
Muchos juegos modernos usan anti-aliasing temporal para aprovechar la información en cuadros previamente renderizados; sin embargo, a veces esto introduce imágenes borrosas y otros artefactos como la distorsión del color alrededor de los bordes.

La suite FidelityFX de AMD incluye un nuevo enfoque conocido como Contrast Adaptive Sharpening (CAS) que utiliza sombreadores de procesamiento posterior para mejorar la calidad de la imagen. CAS mejora los detalles en el interior de un objeto, al tiempo que mantiene los gradientes suaves creados por el suavizado como se ilustra en la Figura 12. Es un sombreador de cómputo de pantalla completa y, por lo tanto, puede funcionar con cualquier tipo de suavizado y es particularmente efectivo cuando se combina con anti-aliasing temporal.
La idea central de CAS es ejecutar un filtro 3×3 y calcular la diferencia entre el máximo aproximado y el mínimo aproximado en el filtro para determinar la cantidad de nitidez adecuada. CAS es extremadamente rápido, toma solo 0.15 milisegundos para un marco de 2560×1440, y se beneficia de una variedad de características en la arquitectura RDNA, como matemática entera para cálculos de direcciones, matemática fp16 para computación, cargas de imagen más rápidas y wave32.
Familia Radeon RX 5700
La serie de GPUs Radeon RX 5700 son los miembros iniciales de la familia «Navi» y se benefician no solo de la arquitectura RDNA, sino también de una tecnología de proceso de 7 nm de última generación que aumenta ligeramente la frecuencia. Estas GPU reemplazan las arquitecturas «Vega» y «Polaris» de la generación anterior y ofrecen mejoras significativas en el rendimiento, la eficiencia energética y la eficiencia del área.
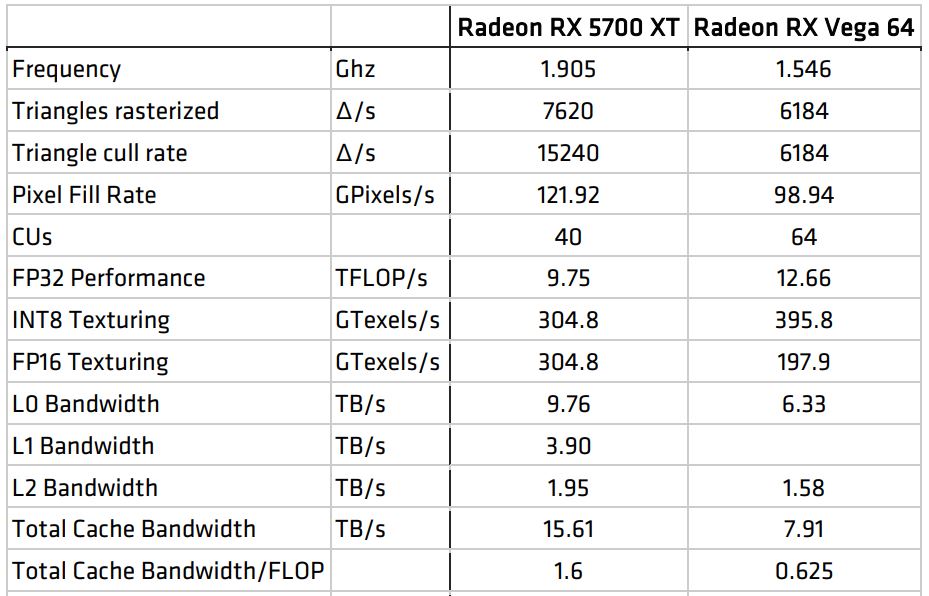
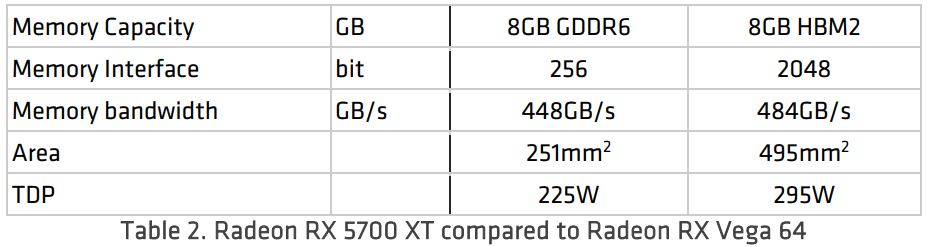
La arquitectura RDNA enfatiza un enfoque elegante y equilibrado del rendimiento con una combinación mucho más rica de ancho de banda de caché y memoria en comparación con el enfoque de cálculo de fuerza bruta en «Vega». Como ilustra la Tabla 2, la arquitectura Radeon RX 5700 XT cuenta con menos cómputo en bruto en la matriz de sombreadores que la Radeon RX Vega 64. Sin embargo, la jerarquía de caché RDNA proporciona un mayor ancho de banda para alimentar la matriz de sombreadores y el ancho de banda de caché superior permite usar el cómputo disponible de forma más efectiva. El Radeon RX 5700 XT ofrece más de 2.5 veces más bytes por FLOP, una mejora tremenda que es crucial para que ofrezca un mejor rendimiento que el Radeon RX Vega 64, especialmente en sombreadores más sofisticados y complejos y sistemas de renderizado basados en cómputo.
La arquitectura RDNA también ofrece mejoras sustanciales en la rasterización, más del doble de la tasa de eliminación de triángulos que no son visibles en una escena, lo que reduce los cuellos de botella en la parte de geometría de pipeline. Del mismo modo, el muestreo de textura y la interpolación para píxeles que usan FP16 por canal se ha duplicado y está a la par con los datos INT8, eliminando cualquier penalización de rendimiento por usar superficies HDR y aumentar la calidad visual.
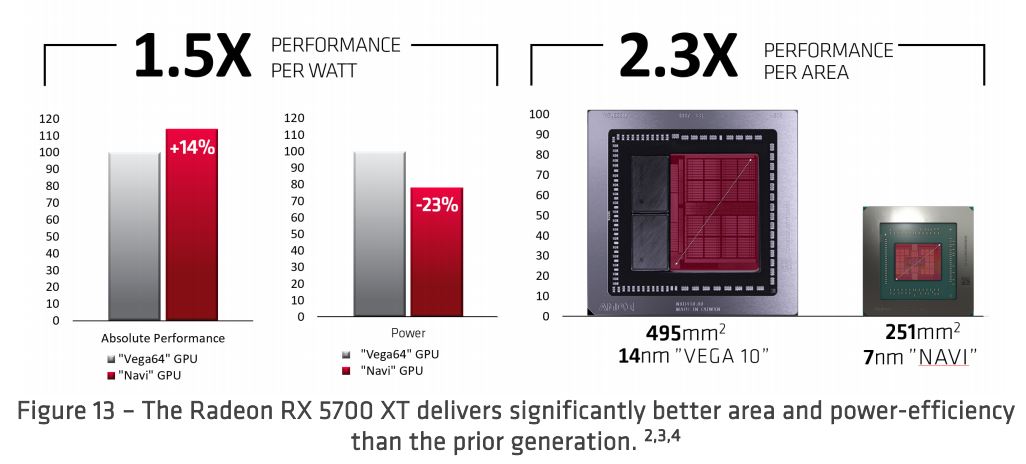
Como ilustra la Figura 13, el impacto general es que el Radeon RX 5700 basado en RDNA ofrece un rendimiento sustancialmente mejor dentro de un die que es la mitad del tamaño en comparación con la generación «Vega». Los factores que contribuyen al aumento del rendimiento de 1.5X RDNA per watt son las ganancias del proceso de 7 nm, las mejoras de rendimiento por reloj y las mejoras de frecuencia y potencia de diseño.
Conclusión
A medida que los gráficos han evolucionado a efectos más ricos y a una fidelidad y precisión cada vez mayores, las limitaciones de gráfica pipeline tradicional se han vuelto cada vez más evidentes. Las técnicas más nuevas, como el modelado de niebla volumétrica o la iluminación en mosaico, usan sombreadores de cómputo más flexibles para aumentar o suplantar la gráfica pipeline tradicional.
Para satisfacer estas necesidades, la arquitectura RDNA de AMD está diseñada para alto rendimiento, escalabilidad, eficiencia y programabilidad. El nuevo flujo de datos wave32 mejora la eficiencia para un código más complejo con ramas, reduce la latencia completando frentes de onda más rápido y permite usar más hardware para ejecutar una carga de trabajo. La memoria caché L1 de gráficos compartidos aumenta drásticamente el ancho de banda disponible para las unidades de cómputo y también ahorra energía y mejora la escalabilidad al reducir el número de solicitudes a la memoria caché y memoria L2 compartida globalmente.
La serie Radeon RX 5700 de 7 nm es la primera implementación de la arquitectura RDNA y un gran paso adelante para la industria. Con la misma potencia, las mejoras arquitectónicas aumentan el rendimiento en un 50% en comparación con la Radeon RX Vega 64 de 14 nm. La serie Radeon RX 5700 es una línea de productos de alta gama, que brinda los beneficios de la arquitectura RDNA a los jugadores de PC. Gracias a la amplia influencia de AMD y sus amplias asociaciones, la arquitectura RDNA se implementará y eventualmente tocará casi todas las partes de la industria. La familia RDNA finalmente crecerá para incluir procesadores de tabletas y teléfonos inteligentes con poca potencia, consolas de juegos, servicios de juegos en la nube y un espectro completo de GPU para juegos de bajo costo al más alto rendimiento, brindando los beneficios de la arquitectura RDNA a millones de dispositivos y personas en todo el planeta.